為什麼要做這個作品
我每天透過 LINE 把文章、影片丟進 Notion 收集箱,收得很勤,但收進去就沉底、幾乎不回頭看,等於沒收。日積月累,收集箱變成一座資料墳場。我想解決的不是「收得不夠多」,而是「收進來的東西從來沒被用到」。目標很單純:做一套會長大、會定期健檢、用到才留的個人知識庫。
用到的工具與架構
整套流程建在四個工具上,各司其職:
- Notion 收集箱:唯一的收集入口,手機上一秒就能丟。
- LINE bot(自己串 API):把看到的連結直接送進收集箱,零阻力。
- Claude Code(AI 代理):負責消化、撈取、健檢,是整套流程的大腦。
- Obsidian vault:知識主體,閱讀筆記和概念卡都存成 Markdown 純文字,可長期保存、不被綁在單一平台。
以前怎麼做/現在怎麼做
以前:丟進收集箱就結束,沒有消化、沒有回用,要查只能在 Notion 裡關鍵字翻、或重新上網找。
flowchart LR
A["看到好文章 / 影片"] --> B["LINE 或手動丟進 Notion 收集箱"]
A --> C["(也曾用 Readwise 畫線)"]
B --> D["收進去就沉底、幾乎不回頭看"]
C --> D
D --> E["要用時翻不到、想不起來"]
E --> F["等於沒收:資料墳場"]
現在:同樣一秒丟進收集箱,但後面接上一整套 AI 消化與回用流程。收進來的東西會被判斷價值、消化成可重複使用的筆記、定期健檢、平常對話時自動被撈出來用。
flowchart TD
A["LINE bot 一秒丟連結"] --> B["Notion 收集箱"]
B --> C{"價值預篩<br/>值不值得消化"}
C -->|低價值| C1["標『跳過』、不寫筆記,省時間也省成本"]
C -->|有價值| D["AI 代理消化"]
D --> E["閱讀筆記 reading<br/>含『對我的應用』"]
D --> F["概念卡 concept<br/>跨多篇合成、可重複使用"]
D --> G["變更日誌 changelog"]
E --> H["品質自檢 + 獨立 AI 對抗式複查"]
F --> H
H --> I["平日對話自動撈取<br/>用『問題強度』決定要不要上網驗證"]
I --> J["定期健檢:標出待驗證 / 斷鏈 / 重複<br/>確認沒用的再清理"]
一篇文章進來後,實際會發生什麼
收集只是開頭,真正的價值在後面這幾步。我說「幫我收這篇」,有價值的文章就會跑完整套流程(低價值的在第 2 步預篩後就跳過):
1. 抓取清洗:把網頁或 YouTube 逐字稿抓下來,清成乾淨的純文字。 2. 價值預篩:先判斷這篇值不值得花成本消化,低價值的直接標「跳過」、不寫筆記,省時間也省 token。 3. 寫閱讀筆記(reading):消化成中文重點,最關鍵的是「對我的應用」段——寫清楚這篇對我的工作或學習能怎麼落地,不只是摘要。 4. 抽概念卡(concept):把跨多篇都會用到的觀念抽成獨立的概念卡,建檔當下就定好信心等級,之後就能被不同文章重複引用。 5. 品質自檢 + 對抗式複查:先自己檢查白話程度、應用具體度、概念獨立性,再開一個「不帶前文」的 AI 代理用新鮮眼光挑毛病、局部修,避免自己寫自己檢查的盲點。 6. 記變更日誌、更新索引:每次新增、擴寫、封存、健檢修正都留痕,並更新主題索引,方便日後查找。
現在的具體成果
這套流程跑了約兩個月,知識庫實際長出來的規模(截至 2026-06-18):
- 73 篇閱讀筆記(reading):每篇都含「對我的應用」段落,寫清楚這篇對我的工作、學習有什麼可落地的用法。
- 352 張概念卡(concept):跨多篇文章合成的精華,比單篇筆記更穩定、更常被重複引用。
- 503 筆變更日誌(changelog):每次新增、擴寫、封存、健檢修正都留痕,知識庫的成長有跡可循。
- 按主題分類:閱讀筆記有「按主題」索引(資安展會、平時資安、AI 工具與工作流、知識管理……),概念卡有獨立索引,要找東西從索引切入,不靠全文亂搜。
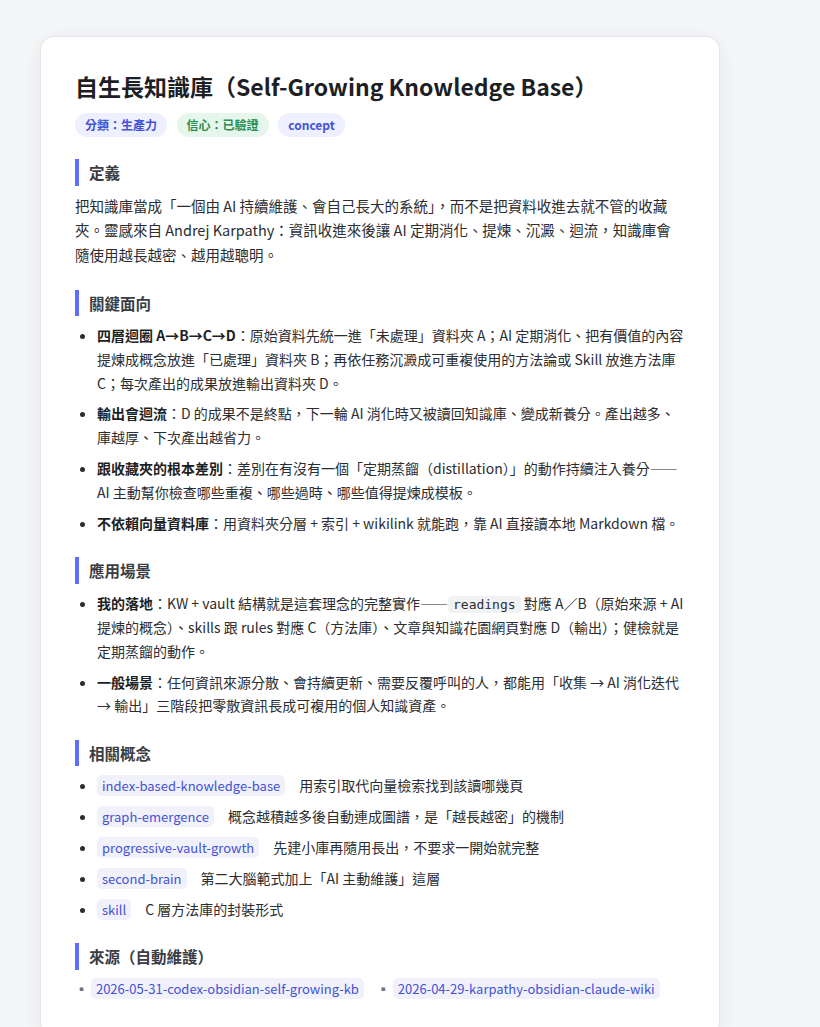
概念卡範例「自生長知識庫」:定義、關鍵面向,以及與其他概念互聯的內部連結(wikilink)——這就是「跨多篇合成、可重複引用」的形態。
最關鍵的成果不是數字,是「回用」真的開始發生。舉個例子:我在準備資安證照,對話聊到「後量子密碼(PQC)」時,知識庫會命中我先前在資安展會收的那幾篇 PQC 筆記、自動墊進回答,我不必自己回想當初收在哪。系統還會用「問題強度」判斷要不要查證——基礎觀念就直接用知識庫,碰到價格、版本、最新動態這類時效性強的,規則會要求它先上網查最新再回答,避免拿過時知識亂答。
知識庫也會定期健檢:把標記「待驗證」的卡片揪出來驗證、修掉斷掉的連結、合併重複的卡片,節奏依實際狀況調整,確定沒用的再清理或封存,不讓它愈長愈肥。
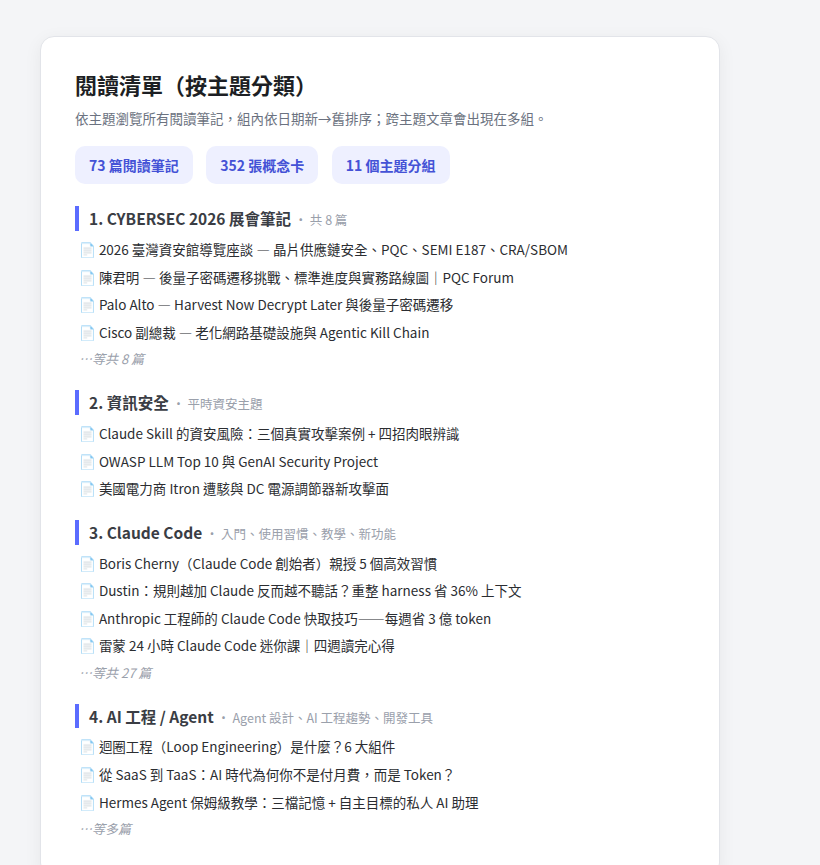
主題分類索引:73 篇閱讀筆記、352 張概念卡,依主題分組,要找東西從索引切入。
設計時做過哪些取捨與調整
做的過程踩過不少坑,幾個關鍵的重新設計:
- 規則三層拆:規則一開始全塞在單一入口檔,AI 每次對話都要扛全部、固定成本太高。後來按「載入時機」拆成常駐入口、條件載入、觸發式工作流三層,不是每次都用得到的就延後載入,省下每次對話的固定載入成本。
- 批次消化並行化:一次消化多篇時,大家會搶同一個變更日誌檔。改成「抓取階段並行、寫入階段序列化」,又快又不衝突。
- 驗證時機前移(出生閘門):知識卡的驗證原本靠查詢次數和健檢排程,效果不好。重設計成「建檔當下就定信心等級」,把驗證移到出生那一刻,不再事後排程補驗,避免卡片建好以後才發現來源太薄弱。
- Notion 改型別避坑:直接改 Notion 欄位型別會清空既有值。踩過一次後改成「先查既有資料、再改型別、最後批次回填」。
- 公開前去識別化 + 對抗式複查:要把設計文件公開時得先去識別化,還跑了獨立 AI 代理用「找碴」角度複查,確認沒有殘留個資才敢公開。
這些設計多半是踩過坑之後才回頭重做的,不是一開始就規劃好的,也是 KW 對我來說最有「自己動手做系統」感的部分。
上迷你課之前,我原本卡在哪
上迷你課之前,我已經習慣用 LINE 串 API,把有興趣的文章和影片自動收進 Notion 收集箱,收得很勤。問題出在收完就放著:時間一久就忘了。最麻煩的是工作或生活中突然想到一個明明看過的觀念,卻只記得「好像在哪篇看過」,在 Notion 裡翻半天找不到,最後乾脆重新 Google,有時候同一篇還收過兩三次才發現重複。收集箱愈長愈大,又一直沒空整理,慢慢就變成一座資料墳場。
學習過程中,哪一步對我最有幫助
最有感的是真的動手把 KW 做出來,第一次看到 AI 在對話中自動把我以前收的筆記撈出來用的那一刻:原來收集是會回來找我的。其中幫助最大的一步,是雷蒙 2-2 講的「規則按載入時機分流」。我本來把所有規則全塞在一個入口檔,AI 每次對話都要扛全部,後來照這個思路拆成三層,整個流程才比較容易串起來。
上完課後,我的工作方式有什麼改變
最具體的改變是「查東西」這件事。以前要用一個資安觀念,得翻筆記或重新上網找,常常找不到就放棄;現在我直接問我的 AI 助理,它會從知識庫撈出對應的閱讀筆記和概念卡,還會自己判斷要不要再上網查證,免得拿過時的資料亂答。我也順手把 Readwise 退掉了,收集、消化、回用收斂成同一條流程。
最後想對其他同學說的話
別一開始就追求一套完美、功能滿滿的系統。先把「收集 → 消化 → 回用」的低阻力循環跑起來,從一個你真的會用的小流程開始,剩下的交給 AI 幫你維護和定期健檢就好。
進一步認識作者
我是一名 IT 工程師,日常顧伺服器、資安與機房,正在一邊考資安證照、一邊學 AI Agent。我習慣把重複的工作流自動化成可複製的個人系統,KW 就是其中一個。目標是朝「超級個體」發展,在持續成長的同時,也希望這些經驗能實際幫到別人。